GitTables: a large-scale corpus of relational tables.
Quick Links
dataset download | paper | github repository | video presentation
Quick Facts
GitTables is a large-scale corpus of relational tables extracted from CSV files in GitHub, that facilitates learning table representation models and applications in e.g. data management, data analysis, etc. We keep expanding GitTables to at least 10M tables (ETA: early 2023).
| Statistic | Value |
|---|---|
| # tables | 1M |
| average # columns | 12 |
| average # rows | 142 |
| # annotated tables (at least 1 column annotation) | 723K+ (DBpedia), 738K+ (Schema.org) |
| # unique semantic types | 835 (DBpedia), 677 (Schema.org) |
About GitTables
GitTables is a large-scale corpus of 1M relational tables extracted from CSV files in GitHub. We aim at growing GitTables to at least 10M tables. Each table is distributed in its original form (e.g. with the original header), and comes with metadata like semantic type annotations of table columns. For these annotations, we used >2K different semantic types from Schema.org and DBpedia.
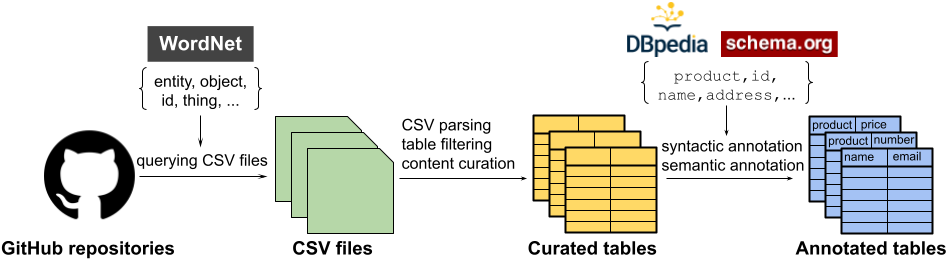
Figure 1 illustrates our approach to creating GitTables, on a high level.
Why GitTables
Existing large-scale table corpora (like WebTables) contain tables extracted from HTML pages, limiting the capability to represent offline tables. These table corpora also lack semantic annotations, like semantic column types.
To train and evaluate table representation models for applications beyond the Web, e.g. data management, additional resources are needed with tables that resemble relational database tables. We built GitTables to facilitate that need.
Example use-cases that GitTables can facilitate that may use table representation models:
- Data search, integration, and validation.
- Data visualization and analysis recommendation.
- Schema completion for e.g. database or knowledge base design.
The dataset
On average the tables have 25 columns and 209 rows, more detailed statistics can be found in the table on top of this page. Each table is stored in a parquet file and comes with metadata, in the form of the original URL, license, and table dimensions. Figure 2 shows an example table.

We also annotated table columns with real-world concepts, semantic types, that the columns refer to. These labels were extracted from the DBpedia and Schema.org ontologies.
We used two different annotation methods:
- Syntactic: string-based matching between column names and the semantic types,
- Semantic: embedding semantic types and column names using a pretrained FastText model trained on the Common Crawl dataset. The annotation corresponds to the most similar semantic type.
Figure 3 presents the distribution of semantic types of the tables per annotation method and ontology.
Downloads
GitTables is hosted on Zenodo which ensures long-term persistence. To facilitate extension and replication of GitTables we publish the code for extraction, curation, and annotation, as well as the ontologies used for annotation.
Dataset downloads
The GitHub Search API requires queries to include a keyword, which we refer to as a topic (e.g. id, object, etc.). We kept this structure in place so each zip file download contains the tables retrieved for a topic.
- GitTables 1M (16.3 GB): the primary corpus of 1M tables used for the analysis in the associated paper.
- GitTables 1M - CSV files (6.8 GB): the CSV files of which the tables were extracted.
- GitTables benchmark - column type detection (3.6 MB): a smaller subset of 1101 tables and associated labels used for benchmarking semantic column type detection.
- GitTables (TBC): the entire dataset of 10M tables with metadata.
Ontology downloads
The tables have been annotated with snapshots of DBpedia and Schema.org. These ontologies are provided in the form of a pickle file. Each pickle contains a pickled Pandas DataFrame with the semantic types per ontology.
Using GitTables
For more detailed instructions for using GitTables, please check the Usage page.
License
GitTables is licensed under the Creative Commons Attributions 4.0 International license (CC BY 4.0). The table data might however be licensed under different licenses as inherited from the GitHub repositories that the CSVs were retrieved from. All tables in the Zenodo dataset with version 0.0.6 have a license that allows distribution of the data. The specific license of each table is attached to the metadata in the parquet file.
Citation
Our paper describes the construction, analysis and use-cases of GitTables in more detail. If you use GitTables, please cite our paper:
@article{hulsebos2023gittables,
title={Gittables: A large-scale corpus of relational tables},
author={Hulsebos, Madelon and Demiralp, {\c{C}}agatay and Groth, Paul},
journal={Proceedings of the ACM on Management of Data},
volume={1},
number={1},
pages={1--17},
year={2023},
publisher={ACM New York, NY, USA}
}
Contact
GitTables is developed by:
- Madelon Hulsebos, University of Amsterdam,
- Çağatay Demiralp, Sigma Computing,
- Paul Groth, University of Amsterdam.
Please consider reporting cases of personal or otherwise undesired tables in GitTables using the form below. Feedback, suggestions and results from projects with GitTables are also very welcome!
Alternatively, you can send an email to m.hulsebos (at) uva.nl.